
上海交大提出ICRDrag:首个上下文区域拖拽模型,实现精准可控图像编辑
上海交大提出ICRDrag:首个上下文区域拖拽模型,实现精准可控图像编辑还在用 DragGAN、DragDiffusion 拖拽修图?点选拖拽容易变形、边界割裂、细节丢失的时代落幕了!ECCV 2026 ICRDrag 首创上下文区域拖拽模型,用掩码精准定位局部区域,移动、缩放、变形全都丝滑自然,兼顾精准度与画面真实感。
来自主题: AI技术研报
8231 点击 2026-07-05 09:47
 搜索
搜索
还在用 DragGAN、DragDiffusion 拖拽修图?点选拖拽容易变形、边界割裂、细节丢失的时代落幕了!ECCV 2026 ICRDrag 首创上下文区域拖拽模型,用掩码精准定位局部区域,移动、缩放、变形全都丝滑自然,兼顾精准度与画面真实感。
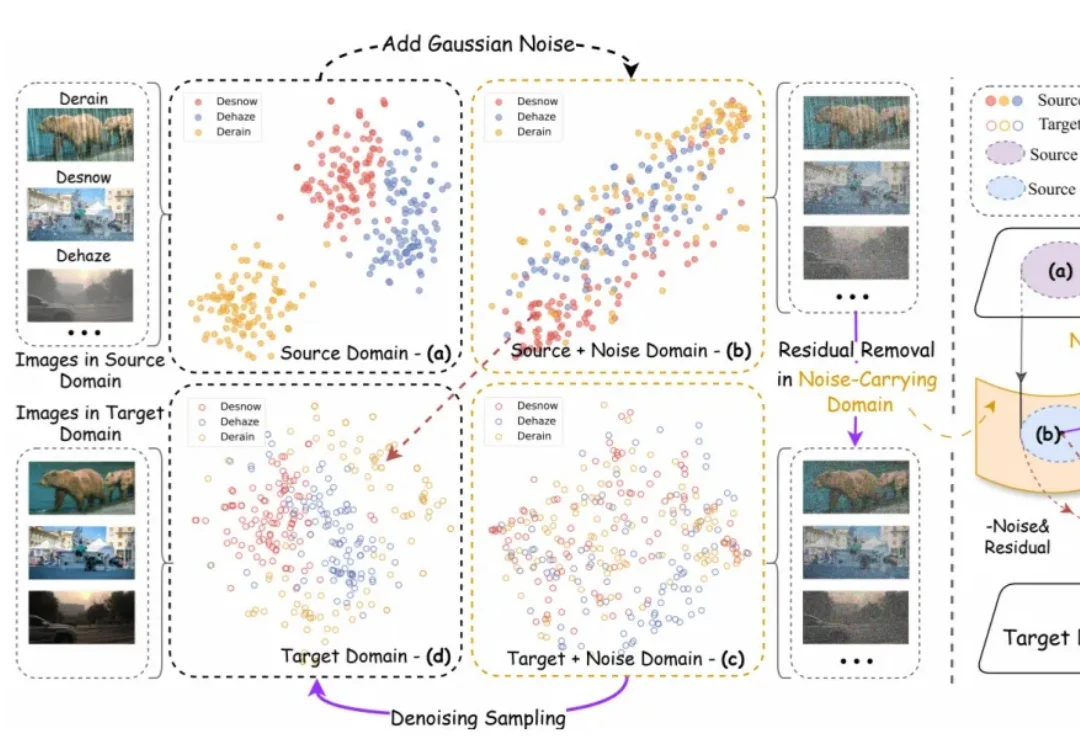
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。

2K 图像 210ms 解码,4K 细节直接生成,传统「解码 + 超分」流水线可能要被重写了。
近期,专为Diffusion模型设计的插件框架——Diffusion Templates正式开源发布。这个框架能大幅降低可控生成技术的训练和使用难度,让开发者能够通过丰富的Templates来精准控制模型的生成结果。

近日,由香港科技大学 MMLab 及合作团队完成的研究工作「UniVidX: A Unified Multimodal Framework for Versatile Video Generation via Diffusion Priors」被计算机图形学顶级会议 SIGGRAPH 2026 正式接收。

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。
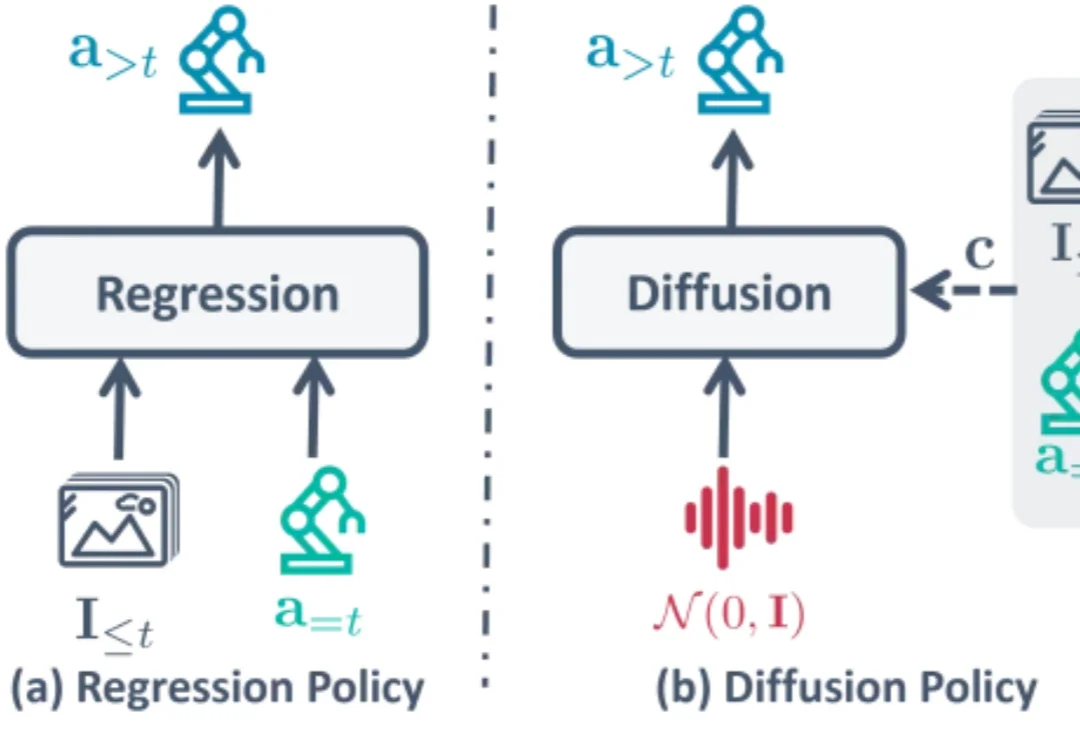
在机器人领域,扩散策略(Diffusion Policy)已经成为了标准模仿学习策略和 VLA 动作生成范式,但其「从随机噪声中迭代解噪」的机制带来了不容忽视的推理延迟。如果机器人不再从随机高斯噪声开始「盲猜」,是否可以基于「刚刚做了什么」来预测「下一步做什么」呢?
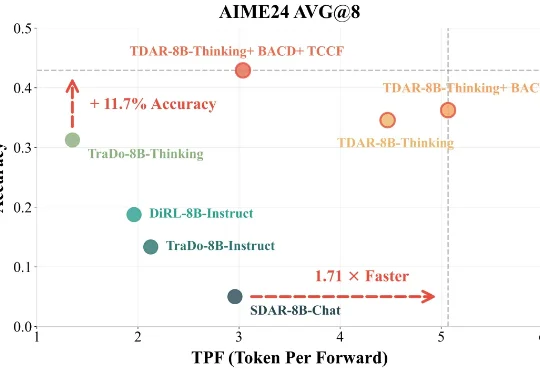
近期,复旦大学 NLP 实验室(FDU NLP)、北京大学知识计算实验室(KCL)联合美团 LongCat Team 提出了一种 Block Diffusion 推理模型 Test-Time Scaling 新框架 TDAR,通过引入 “粗思考,细求证” (Think Coarse Critic Fine, TCCF) 范式与有界自适应置信度解码
扩散语言模型(Diffusion Language Models, DLLMs)因其多种潜在的特性而备受关注,如能加速的非自回归并行生成特性,能直接起草编辑的特性,能数据增强的特性。然而,其模型能力往往落后于同等规模的强力自回归(AR)模型。